1. 存储器层次化结构
存储器有很多种类,我们常见的有内存、磁盘,还有平时看不到的集成在CPU内部的寄存器、高速缓存等。
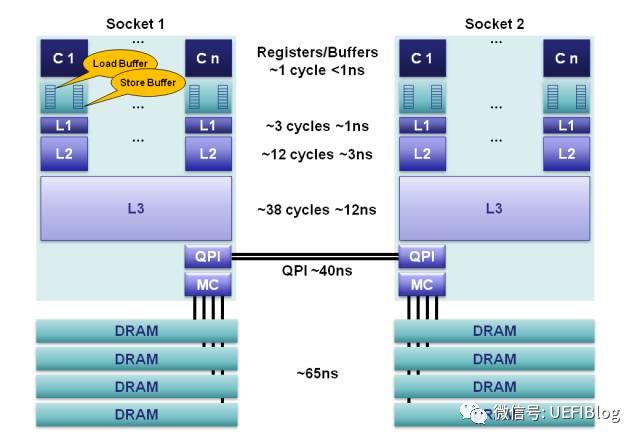
存储器是分层次的,离CPU越近的存储器,速度越快,每字节的成本越高,同时容量也因此越小。寄存器速度最快,离CPU最近,成本最高,所以个数容量有限,其次是高速缓存(缓存也是分级,有L1,L2等缓存),再次是主存(普通内存),再次是本地磁盘。
寄存器的速度最快,可以在一个时钟周期内访问,其次是高速缓存,可以在几个时钟周期内访问,普通内存可以在几十个或几百个时钟周期内访问。
正常来说,存储器的容量和性能应该伴随着CPU的速度和性能提升而提升,以匹配CPU的数据处理。但随着时间的推移,CPU和存储器在性能上的发展差异越来越大,存储器在性能增长越来越跟不上CPU性能发展的需要。
那怎么办呢?
为了缩小存储器和CPU之间的性能差距,通常在计算机内部采用层次化的存储器体系结构,以此来发挥出存储器的综合性能。
存储器层次化结构如下:

最上层的是寄存器,存取时间极快,但容量小。其次是高速缓存,存取时间次之,容量比寄存器大一些。再往下就是我们常见的内存、硬盘,存取速度递减,但容量越来越大。
CPU在访问数据时,数据一般在相邻两层之间复制传送,且总是从慢速存储器复制到快速存储器,通过这种方式保证CPU的速度和存储器的速度相匹配。
2. cache介绍
什么是cache
Cache Memory也被称为Cache,是存储器子系统的组成部分,存放着程序经常使用的指令和数据,这就是Cache的传统定义。从广义的角度上看,Cache是快设备为了缓解访问慢设备延时的预留的Buffer,从而可以在掩盖访问延时的同时,尽可能地提高数据传输率。 快和慢是一个相对概念,与微架构(Microarchitecture)中的 L1/L2/L3 Cache相比, DDR内存是一个慢速设备;在磁盘 I/O 系统中,DDR却是快速设备,在磁盘 I/O 系统中,仍在使用DDR内存作为磁介质的Cache。在一个微架构中,除了有L1/L2/L3 Cache之外,用于虚实地址转换的各级TLB, MOB( Memory Ordering Buffers)、在指令流水线中的ROB,Register File和BTB等等也是一种Cache。我们这里的Cache,是狭义 Cache,是CPU流水线和主存储器的 L1/L2/L3 Cache。
cache,中译名高速缓冲存储器,其作用是为了更好的利用局部性原理,减少CPU访问主存的次数。简单地说,CPU正在访问的指令和数据,其可能会被以后多次访问到,或者是该指令和数据附近的内存区域,也可能会被多次访问。因此,第一次访问这一块区域时,将其复制到cache中,以后访问该区域的指令或者数据时,就不用再从主存中取出。
各级cache读取延迟
L1cache,L2cache,L3cache,虽然它们都是由CAM(Content Addressable Memory )为主体的tag和SRAM组成的,但是区别却是明显的:L1(先不考虑指令和数据L1的不同)是为了更快的速度访问而优化过的,它用了更多/更复杂/更大的晶体管,从而更加昂贵和更加耗电;L2相对来说是为提供更大的容量优化的,用了更少/更简单的晶体管,从而相对便宜和省电。同样的道理还可以推广到L2和L3上。
在同一代制程中,单位面积可以放入晶体管的数目是确定的,这些晶体管如果都给L1则容量太少,Cache命中率(Hit Rate)严重降低,功耗上升太快;如果都给L2,容量大了但延迟提高了一个数量级:
如何平衡L1、L2和L3,用固定的晶体管数目达成最好的综合效果,这是一种平衡的艺术。在多年实践之后,现在已经相对固定下来,Intel和AMD的L1 Cache命中率,现在往往高于95%,增加更多的L1效果不是很显著,现在更多的是增大L3,以达到花同样的代价,干更多的事的目的。
为什么cache不会越做越大
L3现在动辄数十M,比以往那是阔绰很多了,但相对摩尔定律增长的内存容量来说则大幅落后。为什么Cache增长这么缓慢?还是Cost的问题。一个最简单的SRAM就要消耗6个晶体管:
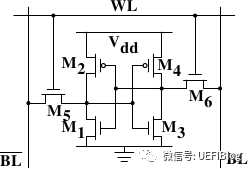
再加上Tag,最少需要数十个晶体管,代价很大。我们花这么大的代价增加Cache,衡量性能的命中率是如何变化的呢?
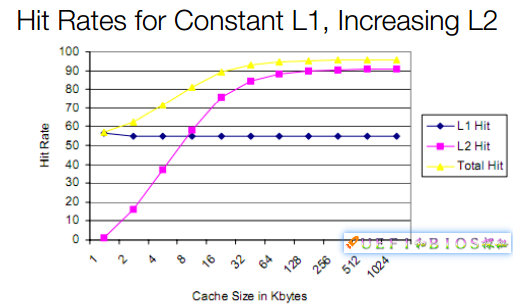
为简化起见,我们假设L1维持在不到60%的命中率(实际情况95%左右)。从图中可以看出,随着L2容量的增加,开始时L2和整体命中率快速提高,这表明提高L2容量效用很明显。随后L2的命中率在容量增加到64KB后增长趋缓,而整体命中率也同时趋缓,最后甚至基本不大变化了。增加同样的晶体管,而受益却越来越少,出现了边际效用递减的问题。
3. 程序访问的局部性
最早期的计算机,在执行一段程序时,都是把硬盘中的数据加载到内存,然后CPU从内存中取出代码和数据执行,在把计算结果写入内存,最终输出结果。
其实这么干,本身没有什么问题,但后来程序运行越来越多,就发现一个规律:内存中某个地址被访问后,短时间内还有可能继续访问这块地址。内存中的某个地址被访问后,它相邻的内存单元被访问的概率也很大。
人们发现的这种规律被称为程序访问的局部性。
程序访问的局部性包含2种:
- 时间局部性:某个内存单元在较短时间内很可能被再次访问
- 空间局部性:某个内存单元被访问后相邻的内存单元较短时间内很可能被访问
出现这种情况的原因很简单,因为程序是指令和数据组成的,指令在内存中按顺序存放且地址连续,如果运行一段循环程序或调用一个方法,又或者再程序中遍历一个数组,都有可能符合上面提到的局部性原理。
那既然在执行程序时,内存的某些单元很可能会经常的访问或写入,那可否在CPU和内存之间,加一个缓存,CPU在访问数据时,先看一下缓存中是否存在,如果有直接就读取缓存中的数据即可。如果缓存中不存在,再从内存中读取数据。
事实证明利用这种方式,程序的运行效率会提高90%以上,这个缓存也叫做高速缓存Cache。
4. 高速缓存cache原理
高速缓存Cache是非常小容量的存储器,它集成在CPU芯片内。为了便于CPU、高速缓存Cache、内存之间的信息交换,内存按块划分,高速缓存Cache按行或槽划分。
CPU对内存、高速缓存Cache进行数据访问的流程如图:
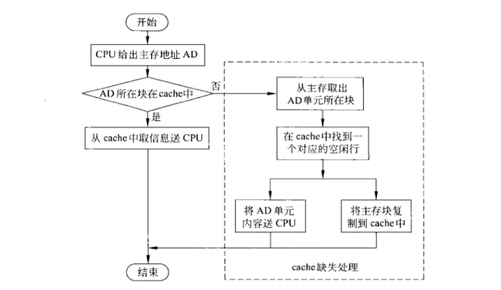
CPU先查询Cache中是否有数据,如果有,直接读取即可。
如果Cache中没有,则从内存中读取数据,同时把数据放入Cache中,然后把数据返回给CPU。
整个流程其实很简单,但对于Cache和内存信息的交换,需要考虑一些问题:
- 对于CPU读取数据,如果Cache中没有数据,从内存中读取数据后,如何分配到Cache中?
- 如果Cache满了,采用什么策略替换?
- 对于CPU写入数据,如何保证Cache和内存数据的一致性?
对于这3个问题,下面依次来分析是如何解决的。
5. CPU和cache的内存映射
对于第一个问题,Cache中没有命中数据时,内存数据是如何分配到Cache中的。
由于内存的容量比Cache容量要大,两者之间的容量不匹配,所以内存数据填充到Cache中,就需要设计一种规则来保证Cache的利用率最大,保证CPU访问Cache的命中率最高。
内存到Cache的映射规则有3种方式:
- 直接映射:每个内存块数据只映射到固定的缓存行中
- 全相联映射:每个内存块数据可以映射到任意缓存行中
- 组相联映射:每个内存块数据可以映射到固定组的任意缓存行中
下面我们分别来看这3种映射方式。
直接映射
访问内存数据会给出一个内存地址,首先把这个内存地址,按位划分为3个字段:标记、Cache行号、块内地址,如图:

然后根据第2个字段的二进制位进行取模运算,得到对应的Cache行号。
找到对应的Cache号后,校验Cache的有效位,如果有效,再比较内存第1个字段的标记与Cache的标记是否一致,如果一致,直接获取Cache中的数据即可。
如果有效位无效,或有效位有效但内存第1个字段的标记与Cache的标记不一致,那么根据内存地址去内存获取数据,然后把对应的Cache行有效位设置为有效,标记设置为与内存标记一致,并在Cache中记录内存的数据,以便下次获取。
具体映射关系如图:
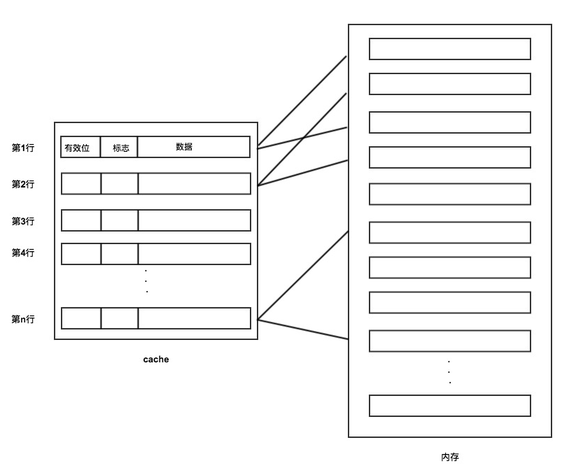
可见Cache与内存的映射可能是一对多的,即不同内存块可能映射到同一Cache行。
这种映射方式比较简单粗暴,如果缓存不命中或内存和Cache标识不一致,就会替换Cache行中的数据。这就可能导致同一Cache行在短时间内被频繁替换,命中率不高。
全相联映射
全相联映射与直接映射方式不同的是,它把内存分成2个字段:标记、块内地址,没有了Cache行号这个字段。

在访问数据时,直接根据内存地址中的标记,去直接遍历对比每一个Cache行,直到找到一致的标记的Cache行,然后访问Cache中的数据即可。
如果遍历完Cache行后,没有找到一致的标记,那么会从内存中获取数据,然后找到空闲的Cache行,直接写入标记和数据即可。
也就是说,这种映射方式,就是哪里有空闲的Cache行,我就把内存块映射到这个Cache行中。在访问时,依次遍历Cache行,直到找到标记一直的Cache行,然后读取数据。
这种方式虽然在空间利用率上保证最大化,但其缺点在于要在Cache中寻找符合标识一致的行的时间要比直接映射的时间久,效率较低。
那有什么方式能集合上面2种方式,发挥各自的优势呢?这就是下面要说的组相联映射方式。
组相联映射方式
组相联映射方式把内存也分为3个字段:标记、Cache组号、块内地址

注意,与直接映射不同的是,第2个字段是组号而不是行号。这种方式把Cache行先进行分组,然后每个分组中包含多个Cache行,如图:
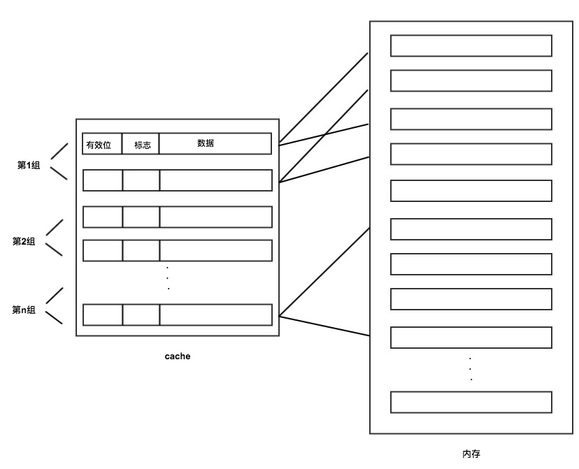
在访问数据时,先根据内存地址中的Cache组号,定位到Cache的分组,然后在这个组内,依次遍历每个行,寻找标记一致的Cache行,如果标记一致则获取数据,不一致则从内存中获取数据后写入当前组内空闲的任意一个Cache行中。
这种方式兼顾了访问速度和空间利用率,使用前2种方式结合的方案,保证缓存命中率最大化。在现实中实际上采用的这种映射方式。
6. cache替换算法
对于上面提的第2个问题,如果Cache满了,如何进行替换?
Cache容量比内存小,所以内存数据映射到Cache时,必然会导致Cache满的情况,那之后的内存映射要替Cache中的哪些行呢?这就需要制定一种策略。
常见的替换算法有如下几种:
- 先进先出算法(FIFO):总是把最早装入Cache的行替换掉,这种算法实现简单,但不能正确反映程序的访问局部性,命中率不高
- 最近最少使用算法(LRU):总是选择最近最少使用的Cache行替换,这种这种算法稍微复杂一些,但可以正确反映程序访问的局部性,命中率最高
- 最不经常使用算法(LFU):总是替换掉Cache中引用次数最少的行,与LRU类似,但没有LRU替换方式更精准
- 随机替换算法(Random):随机替换掉Cache中的行,与使用情况无关,命中率不高
现实使用最多的是最近最少使用算法(LRU)进行Cache行的替换方案,这种方案使得缓存的命中率最高。
7. cache的一致性问题
上面提的第3个问题,对于写入的数据,如何保证Cache和内存数据的一致性?
试想,如果CPU想要修改某个内存的数据,这块内存的数据刚好在Cache中存在,那么是不是要同时更新Cache中的数据?
这个写入数据的过程,通常采用2种方式:
- 全写法(通写法/直写法/写直达法)
- 回写法(写回法)
全写法
在写操作时,如果Cache命中,则同时写Cache和内存。
如果Cache中不命中,则分为以下2种情况:
- 写分配法:先更新内存数据,然后再写入空闲的Cache行中,保证Cache有数据,提高了缓存命中率,但增加了写入Cache的开销
- 非写分配法:只更新内存数据,不写入Cache,只有等访问不命中时,再进行缓存写入
另外,这种方式为了减少内存的写入开销,一般会在Cache和内存之间加一个写缓冲队列,在CPU写入Cache的同时,也会写入缓冲队列,然后由存储控制器将缓冲队列写入内存。
如果在写操作不频繁的情况下,效果很好。但如果写操作频繁,则会导致写缓冲队列饱和而发生阻塞。
回写法
这种方式在写操作时,如果Cache命中,则只更新Cache而不更新内存。
如果Cache不命中,则从内存中读取内容,写入Cache并更新为最新内容。
这种方式不会主动更新内存,只有在Cache被再次修改时,才将内容一次性写入内存。这样做的好处是减少了写内存的次数,大大降低内存带宽需求。但有可能在某个时间点,Cache和内存中的数据会出现不一致的情况。
8. 影响Cache的性能因素
既然Cache在CPU访问数据时提升的效率这么高,那决定Cache性能的因素有哪些?
决定访问性能的重要因素之一就是Cache的命中率,它与许多因素有关,具体涉及如下:
- Cache容量:容量越大,缓存数据越多,命中率越高
- 内存块大小:大的内存交换单位能更好地利用空间局部性,但过大也会导致命中率降低,必须适中
除此之外,如何设计Cache也会影响到它的性能:
- 多级Cache:现在的CPU会采用3级Cache,最大程度的提升命中率
- 内存、总线、Cache连接结构:设计一个效率高的传输通道,能够提升Cache的访问速度
- 内存结构与Cache配合:在访问不命中时,会去访问内存,设计效率高的传输通道与Cache配合也可以提升Cache的性能
9. HDD和SSD的区别
主要是顺序读取和随机读取。
吞吐量
顺序读取看吞吐量:指单位时间内可以成功传输的数据数量。顺序读写频繁的应用,如视频点播,关注连续读写性能、数据吞吐量是关键衡量指标。它主要取决于磁盘阵列的架构,通道的大小以及磁盘的个数。不同的磁盘阵列存在不同的架构,但他们都有自己的内部带宽,一般情况下,内部带宽都设计足够充足,不会存在瓶颈。磁盘阵列与服务器之间的数据通道对吞吐量影响很大,比如一个2Gbps的光纤通道,其所能支撑的最大流量仅为250MB/s。最后,当前面的瓶颈都不再存在时,硬盘越多的情况下吞吐量越大。
IOPS
随机读取看IOPS:IOPS(Input/Output Per Second)即每秒的输入输出量(或读写次数),即指每秒内系统能处理的I/O请求数量。随机读写频繁的应用,如小文件存储等,关注随机读写性能,IOPS是关键衡量指标。可以推算出磁盘的IOPS = 1000ms / (Tseek + Trotation + Transfer),如果忽略数据传输时间,理论上可以计算出随机读写最大的IOPS。常见磁盘的随机读写最大IOPS为: - 7200rpm的磁盘 IOPS = 76 IOPS - 10000rpm的磁盘IOPS = 111 IOPS - 15000rpm的磁盘IOPS = 166 IOPS
HDD
HDD中,顺序读取:预读机制,很快,
随机读取:因为要寻道时间+旋转时间+传输时间
寻道时间一般:3-15ms
旋转时间与转速有关:7200rpm一般4ms,15000rpm一般2ms
机械硬盘的连续读写性能很好,但随机读写性能很差,这主要是因为磁头移动到正确的磁道上需要时间,随机读写时,磁头需要不停的移动,时间都浪费在了磁头寻址上,所以性能不高。
SSD
SSD中,顺序读取:
随机读取:在SSD中,一般会维护一个mapping table,维护逻辑地址到物理地址的映射。每次读写时,可以通过逻辑地址直接查表计算出物理地址,与传统的机械磁盘相比,省去了寻道时间和旋转时间。
区别
所以SSD与HDD的主要区别:
从NAND Flash的原理可以看出,其和HDD的主要区别为
- 定位数据快:HDD需要经过寻道和旋转,才能定位到要读写的数据块,而SSD通过mapping table直接计算即可
- 读取速度块:HDD的速度取决于旋转速度,而SSD只需要加电压读取数据,一般而言,要快于HDD
因此,在顺序读测试中,由于定位数据只需要一次,定位之后,则是大批量的读取数据的过程,此时,HDD和SSD的性能差距主要体现在读取速度上,HDD能到200M左右,而普通SSD是其两倍。
在随机读测试中,由于每次读都要先定位数据,然后再读取,HDD的定位数据的耗费时间很多,一般是几毫秒到十几毫秒,远远高于SSD的定位数据时间(一般0.1ms左右),因此,随机读写测试主要体现在两者定位数据的速度上,此时,SSD的性能是要远远好于HDD的。
10. 总结
本篇文章主要介绍了高速缓存Cache的重点知识,总结如下:
- 程序运行有访问局部性的规律:时间局部性、空间局部性
- 内存与Cache的映射方式有3种:直接映射、全相联映射、组相联映射,其中组相联映射方式命中率最高
- Cache的替换算法有4种:先进先出(FIFO)、最近最少使用(LRU)、最不经常使用(LFU)、随机(Random),其中最近最少使用算法的命中率最高
- 保证内存与Cache的一致性方案有2种:全写法、回写法
- 影响Cache的性能因素有:容量、内存块大小、Cache组合、内存结构与传输通道设计等
- HDD和SSD在顺序读取,随机读取的不同