classSolution(object): defsubsetsWithDup(self, nums): """ :type nums: List[int] :rtype: List[List[int]] """ res = [] nums.sort() defhelper(idx,tmp): res.append(tmp) for i inrange(idx,len(nums)): if i > idx and nums[i] == nums[i-1]: continue helper(i+1,tmp+[nums[i]]) helper(0,[]) return res
# Definition for singly-linked list. # class ListNode(object): # def __init__(self, x): # self.val = x # self.next = None
classSolution(object): defreverseBetween(self, head, m, n): """ :type head: ListNode :type m: int :type n: int :rtype: ListNode """ ifnot head or m == n: return head pre = dummy = ListNode(None) dummy.next = head for i inrange(m-1): pre = pre.next cur = pre.next for i inrange(n-m): tmp = cur.next cur.next = tmp.next tmp.next = pre.next pre.next = tmp return dummy.next
classSolution(object): defrestoreIpAddresses(self, s): """ :type s: str :rtype: List[str] """ res = [] n = len(s) defbacktrack(i,tmp,flag): if i == n and flag == 0: res.append(tmp[:-1]) return if flag < 0: return for j inrange(i, i+3): if j < n: if i == j and s[j] == '0': backtrack(j+1,tmp+s[j]+'.',flag-1) break if0 < int(s[i:j+1]) <= 255: backtrack(j+1,tmp+s[i:j+1]+'.',flag-1) backtrack(0,'',4) return res
# Definition for a binary tree node. # class TreeNode(object): # def __init__(self, x): # self.val = x # self.left = None # self.right = None
classSolution(object): definorderTraversal(self, root): """ :type root: TreeNode :rtype: List[int] """ ifnot root: return [] res = [] if root.left: res += self.inorderTraversal(root.left) res.append(root.val) if root.right: res += self.inorderTraversal(root.right) return res
# Definition for a binary tree node. # class TreeNode(object): # def __init__(self, x): # self.val = x # self.left = None # self.right = None
classSolution(object): definorderTraversal(self, root): """ :type root: TreeNode :rtype: List[int] """ ifnot root: return [] res = [] stack = [] p = root while p orlen(stack): while p: stack.append(p) p = p.left if stack: p = stack.pop() res.append(p.val) p = p.right return res
# Definition for a binary tree node. # class TreeNode(object): # def __init__(self, x): # self.val = x # self.left = None # self.right = None
classSolution(object): defgenerateTrees(self, n): """ :type n: int :rtype: List[TreeNode] """ if n == 0: return [] defhelper(nums): ifnot nums: return [None] res = [] for i inrange(len(nums)): for l in helper(nums[:i]): for r in helper(nums[i+1:]): node = TreeNode(nums[i]) node.left = l node.right = r res.append(node) return res return helper(list(range(1,n+1)))
# Definition for a binary tree node. # class TreeNode(object): # def __init__(self, x): # self.val = x # self.left = None # self.right = None
classSolution(object): defisValidBST(self, root): """ :type root: TreeNode :rtype: bool """ stack = [] p = root pre = None while p or stack: while p: stack.append(p) p = p.left if stack: p = stack.pop() if pre and p.val <= pre.val: returnFalse pre = p p = p.right returnTrue
# Definition for a binary tree node. # class TreeNode(object): # def __init__(self, x): # self.val = x # self.left = None # self.right = None
classSolution(object): defrecoverTree(self, root): """ :type root: TreeNode :rtype: None Do not return anything, modify root in-place instead. """ first = second = None pre = None stack = [] p = root while p or stack: while p: stack.append(p) p = p.left if stack: p = stack.pop() ifnot first and pre and pre.val > p.val: first = pre if first and pre and pre.val > p.val: second = p pre = p p = p.right first.val,second.val = second.val,first.val
# Definition for singly-linked list. # class ListNode(object): # def __init__(self, x): # self.val = x # self.next = None
classSolution(object): defdeleteDuplicates(self, head): """ :type head: ListNode :rtype: ListNode """ whilenot head ornot head.next: return head dummy = ListNode(-1) dummy.next = head slow = dummy fast = dummy.next while fast: if fast.nextand fast.val == fast.next.val: tmp = fast.val while fast and fast.val == tmp: fast = fast.next else: slow.next = fast slow = fast fast = fast.next slow.next = fast return dummy.next
# Definition for singly-linked list. # class ListNode(object): # def __init__(self, x): # self.val = x # self.next = None
classSolution(object): defdeleteDuplicates(self, head): """ :type head: ListNode :rtype: ListNode """ whilenot head ornot head.next: return head dummy = cur = pre = ListNode(None) while head: while head and ((head.val == pre.val) or (head.nextand head.val == head.next.val)): pre = head head = head.next cur.next = head cur = cur.next if head: head = head.next return dummy.next
3. 删除排序链表中的重复项(Easy)
给定一个排序链表,删除所有重复的元素,使得每个元素只出现一次。
示例 1:
1 2
输入: 1->1->2 输出: 1->2
示例 2:
1 2
输入: 1->1->2->3->3 输出: 1->2->3
解答:
思路:dummy大法
很简单啊,dummy大法在解决这种链表问题上,很有用。
1 2 3 4 5 6 7 8 9 10 11 12
classSolution(object): defdeleteDuplicates(self, head): """ :type head: ListNode :rtype: ListNode """ dummy = head while head: while head.nextand head.next.val == head.val: head.next = head.next.next# skip duplicated node head = head.next# not duplicate of current node, move to next node return dummy
classSolution(object): deflargestRectangleArea(self, heights): """ :type heights: List[int] :rtype: int """ res = 0 n = len(heights) for i inrange(n): l = i r = i while l >= 0and heights[l] >= heights[i]: l -= 1 while r < n and heights[r] >= heights[i]: r += 1 res = max(res,heights[i]*(r-l-1)) return res
暴力解法2:思路很简单,同样也超时
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution(object): deflargestRectangleArea(self, heights): """ :type heights: List[int] :rtype: int """ res = 0 n = len(heights) for i inrange(n): minHeight = float('inf') for j inrange(i,n): minHeight = min(minHeight,heights[j]) res = max(res,minHeight*(j-i+1)) return res
思路三:这个题是真的难。。。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution(object): deflargestRectangleArea(self, heights): """ :type heights: List[int] :rtype: int """ stack = [-1] res = 0 n = len(heights) for i inrange(n): while stack[-1] != -1and heights[stack[-1]] >= heights[i]: tmp = stack.pop() res = max(res,heights[tmp] * (i-stack[-1]-1)) stack.append(i) while stack[-1] != -1: tmp = stack.pop() res = max(res,heights[tmp]*(n-stack[-1]-1)) return res
我个人觉得,下面这个解答,更容易理解。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution(object): deflargestRectangleArea(self, heights): """ :type heights: List[int] :rtype: int """ heights.append(0) area, stack = 0, [-1] for idx, height inenumerate(heights): while height < heights[stack[-1]]: h = heights[stack.pop()] w = idx - stack[-1] - 1 area = max(w*h, area) stack.append(idx) return area
while right < len(s): if lookup[s[right]] > 0: count -= 1 lookup[s[right]] -= 1 right += 1
得到可行的窗口后,将left指针逐个右移,若得到的窗口依然可行,则更新最小窗口大小。
1 2 3 4 5 6 7 8
while count == 0: if min_len > right-left: min_len = right-left res = s[left:right] if lookup[s[left]] == 0: count += 1 lookup[s[left]] += 1 left += 1
若窗口不再可行,则跳转至 2。
1 2 3 4 5 6 7 8 9 10 11 12 13
while right < len(s): if lookup[s[right]] > 0: count -= 1 lookup[s[right]] -= 1 right += 1 while count == 0: if min_len > right-left: min_len = right-left res = s[left:right] if lookup[s[left]] == 0: count += 1 lookup[s[left]] += 1 left += 1
classSolution(object): defcombine(self, n, k): """ :type n: int :type k: int :rtype: List[List[int]] """ res = [] defhelper(i,k,tmp): if k == 0: res.append(tmp) for j inrange(i,n+1): helper(j+1,k-1,tmp+[j]) helper(1,k,[]) return res
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝 int len = removeDuplicates(nums);
// 在函数里修改输入数组对于调用者是可见的。 // 根据你的函数返回的长度, 它会打印出数组中该长度范围内的所有元素。 for (int i = 0; i < len; i++) { print(nums[i]); }
解答:
思路:
1 2 3 4 5 6 7 8 9 10 11 12
classSolution(object): defremoveDuplicates(self, nums): """ :type nums: List[int] :rtype: int """ i = 0 for n in nums: if i < 2or n != nums[i-2]: nums[i] = n i += 1 return i
此题可以有通用模板,将2改成k的话:
1 2 3 4 5 6 7 8
classSolution: defremoveDuplicates(self, nums, k): i = 0 for n in nums: if i < k or n != nums[i-k]: nums[i] = n i += 1 return i
classSolution(object): defminDistance(self, word1, word2): """ :type word1: str :type word2: str :rtype: int """ n = len(word1) m = len(word2) if n == 0or m == 0: returnmax(n,m) dp = [[i+j for j inrange(m+1)] for i inrange(n+1)] for i inrange(1,n+1): for j inrange(1,m+1): tmp = 0if word1[i-1] == word2[j-1] else1 dp[i][j] = min(dp[i-1][j]+1,dp[i][j-1]+1,dp[i-1][j-1]+tmp) return dp[-1][-1]
3. 矩阵置零(Medium)
给定一个 m x n 的矩阵,如果一个元素为 0,则将其所在行和列的所有元素都设为 0。请使用原地算法。
最后,我们迭代原始矩阵,对于每个格子检查行 r 和列 c 是否被标记过,如果是就将矩阵格子的值设为 0。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
classSolution(object): defsetZeroes(self, matrix): """ :type matrix: List[List[int]] :rtype: None Do not return anything, modify matrix in-place instead. """ row = len(matrix) col = len(matrix[0]) rows,cols = set(),set() for i inrange(row): for j inrange(col): if matrix[i][j] == 0: rows.add(i) cols.add(j) for i inrange(row): for j inrange(col): if i in rows or j in cols: matrix[i][j] = 0
输入: words = ["This", "is", "an", "example", "of", "text", "justification."] maxWidth = 16 输出: [ "This is an", "example of text", "justification. " ]
示例 2:
1 2 3 4 5 6 7 8 9 10 11 12
输入: words = ["What","must","be","acknowledgment","shall","be"] maxWidth = 16 输出: [ "What must be", "acknowledgment ", "shall be " ] 解释: 注意最后一行的格式应为 "shall be " 而不是 "shall be", 因为最后一行应为左对齐,而不是左右两端对齐。 第二行同样为左对齐,这是因为这行只包含一个单词。
示例 3:
1 2 3 4 5 6 7 8 9 10 11 12 13
输入: words = ["Science","is","what","we","understand","well","enough","to","explain", "to","a","computer.","Art","is","everything","else","we","do"] maxWidth = 20 输出: [ "Science is what we", "understand well", "enough to explain to", "a computer. Art is", "everything else we", "do " ]
解答:
思路:
这道题确实难。
解答和思考过程参考题解部分。
思路: 首先要理顺题意,给定一堆单词,让你放在固定长度字符串里
两个单词之间至少有一个空格,如果单词加空格长度超过maxWidth,说明该单词放不下,比如示例1:当我们保证this is an 再加入example变成this is an example总长度超过maxWidth,所以这一行只能放下this is an 这三个单词;
this is an长度小于maxWidth,我们考虑分配空格,并保证左边空格数大于右边的
最后一行,要尽量靠左,例如示例2的:”shall be “
我们针对上面三个问题,有如下解决方案.
先找到一行最多可以容下几个单词;
分配空格,例如this is an ,对于宽度为maxWidth,我们可以用maxWidth - all_word_len 与需要空格数商为 单词间 空格至少的个数,余数是一个一个分配给左边.就能保证左边空格数大于右边的.例如 16 - 8 = 8 ,a = 8 / 2, b = 8 % 2两个单词间要有4个空格,因为余数为零不用分配;
classSolution(object): deffullJustify(self, words, maxWidth): """ :type words: List[str] :type maxWidth: int :rtype: List[str] """ res = [] n = len(words) i = 0 defone_row_words(i): left = i cur_row = len(words[i]) i += 1 while i < n: if cur_row + len(words[i]) + 1 > maxWidth: break cur_row += len(words[i]) + 1 i += 1 return left,i while i < n: left,i = one_row_words(i) one_row = words[left:i] if i == n: res.append(' '.join(one_row).ljust(maxWidth,' ')) break all_word_len = sum(len(i) for i in one_row) space_num = i - left - 1 remain_space = maxWidth - all_word_len if space_num: a,b = divmod(remain_space,space_num) tmp = '' for word in one_row: if tmp: tmp += ' '*a if b: tmp += ' ' b -= 1 tmp += word res.append(tmp.ljust(maxWidth,' ')) return res
classSolution(object): defmySqrt(self, x): """ :type x: int :rtype: int """ if x == 0: return0 if x == 1: return1 l ,r = 0,x-1 while l <= r: mid = l +((r-l)>>1) if mid * mid <= x and (mid+1) * (mid +1) > x: return mid elif mid * mid <x: l = mid + 1 else: r = mid - 1
思路二:牛顿法
1 2 3 4 5 6 7 8 9 10
classSolution(object): defmySqrt(self, x): """ :type x: int :rtype: int """ t = x while t * t >x: t = (t + x/t)/2 return t
classSolution(object): defclimbStairs(self, n): """ :type n: int :rtype: int """ a = 1 b = 2 if n == 1: return1 if n == 2: return2 for i inrange(2,n): a,b = b,a+b return b
classSolution(object): defuniquePaths(self, m, n): """ :type m: int :type n: int :rtype: int """ if m<1or n<1: return0 dp = [[1] * m for i inrange(n)] for i inrange(1,n): for j inrange(1,m): dp[i][j] = dp[i-1][j] + dp[i][j-1] return dp[-1][-1]
思路二:降低空间复杂度的动态规划
好像所有的动态规划都可以做到空间复杂度降低。
优化:因为我们每次只需要 dp[i-1][j],dp[i][j-1]
所以我们只要记录这两个数,直接看代码吧!
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution(object): defuniquePaths(self, m, n): """ :type m: int :type n: int :rtype: int """ if m<1or n<1: return0 cur = [1]*n for i inrange(1,m): for j inrange(1,n): cur[j] += cur[j-1] return cur[-1]
classSolution(object): defuniquePathsWithObstacles(self, obstacleGrid): """ :type obstacleGrid: List[List[int]] :rtype: int """ self.res = 0 m = len(obstacleGrid) n = len(obstacleGrid[0]) deftravel(x,y): if x == m-1and y == n-1and obstacleGrid[x][y] != 1: self.res += 1 if x +1 < m and obstacleGrid[x+1][y] != 1: travel(x+1,y) if y+1 < n and obstacleGrid[x][y+1] != 1: travel(x,y+1) if obstacleGrid[0][0] == 1: return0 travel(0,0) return self.res
classSolution(object): defmerge(self, intervals): """ :type intervals: List[List[int]] :rtype: List[List[int]] """ res = [] for i insorted(intervals,key = lambda x:x[0]): if res and i[0] <= res[-1][1]: res[-1][1] = max(res[-1][1],i[1]) else: res.append(i) return res
classSolution(object): definsert(self, intervals, newInterval): """ :type intervals: List[Interval] :type newInterval: Interval :rtype: List[Interval] """ ifnot intervals orlen(intervals) == 0: return [newInterval] idx = -1 for i inrange(len(intervals)): if intervals[i].start > newInterval.start: idx = i break if idx != -1: intervals.insert(i, newInterval) else: intervals.append(newInterval) res = [] for interval in intervals: if res and res[-1].end >= interval.start: res[-1].end = max(res[-1].end, interval.end) else: res.append(interval) return res
3. 最后一个单词的长度(Easy)
给定一个仅包含大小写字母和空格 ' ' 的字符串,返回其最后一个单词的长度。
如果不存在最后一个单词,请返回 0 。
说明:一个单词是指由字母组成,但不包含任何空格的字符串。
示例:
1 2
输入: "Hello World" 输出: 5
解答:
思路:
很简单
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution(object): deflengthOfLastWord(self, s): """ :type s: str :rtype: int """ n = len(s) if n == 0: return0 res = 0 flag = 0 for i inrange(n-1,-1,-1): if s[i] != ' ': res += 1 flag = 1 elif s[i] == ' 'and flag: return res return res
思路二:
直接找最后一个单词
先找最后一个单词最后一个字母
再找最后一个单词第一个字母
1 2 3 4 5 6 7 8 9 10
classSolution: deflengthOfLastWord(self, s: str) -> int: end = len(s) - 1 while end >= 0and s[end] == " ": end -= 1 if end == -1: return0 start = end while start >= 0and s[start] != " ": start -= 1 return end - start
classSolution(object): defgenerateMatrix(self, n): """ :type n: int :rtype: List[List[int]] """ seen = [[False]*n for _ inrange(n)] dr = [0,1,0,-1] dc = [1,0,-1,0] r,c,di = 0,0,0 ans = [[-1]*n for _ inrange(n)] for i inrange(1,n*n+1): ans[r][c] = i seen[r][c] = True next_r,next_c = r+dr[di],c+dc[di] if0<= next_r<n and0<=next_c<n andnot seen[next_r][next_c]: r = next_r c = next_c else: di = (di+1)%4 r,c = r+dr[di],c+dc[di] return ans
classSolution(object): defgetPermutation(self, n, k): """ :type n: int :type k: int :rtype: str """ s = ''.join([str(i) for i inrange(1, n+1)]) print(s) defpermunation(s): iflen(s) == 0: return iflen(s) == 1: return [s] res = [] for i inrange(len(s)): x = s[i] xs = s[:i] + s[i+1:] for j in permunation(xs): res.append(x+j) return res return permunation(s)[k-1]
classSolution(object): defgetPermutation(self, n, k): """ :type n: int :type k: int :rtype: str """ res = '' fac = [1] * (n+1) for i inrange(1,n+1): fac[i] = fac[i-1]*i nums = [i for i inrange(1,n+1)] k -= 1 for i inrange(1,n+1): idx = k/fac[n-i] res += str(nums[idx]) nums.pop(idx) k -= idx * fac[n-i] return res
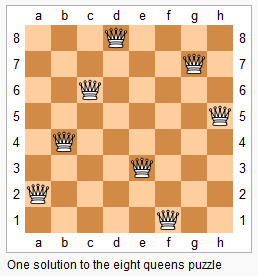
classSolution(object): defsolveNQueens(self, n): """ :type n: int :rtype: List[List[str]] """ defdfs(cols_lst, xy_diff, xy_sum): cur_row = len(cols_lst) if cur_row == n: ress.append(cols_lst) for col inrange(n): if col notin cols_lst and cur_row - col notin xy_diff and cur_row + col notin xy_sum: dfs(cols_lst+[col], xy_diff+[cur_row-col], xy_sum+[cur_row+col]) ress = [] dfs([], [], []) return [['.' * i + 'Q' + '.' * (n-i-1) for i in res] for res in ress]
classSolution(object): deftotalNQueens(self, n): """ :type n: int :rtype: int """ defdfs(col_list,xy_diff,xy_sum): cur_row = len(col_list) if cur_row == n: ress.append(col_list) for col inrange(n): if col notin col_list and cur_row-col notin xy_diff and cur_row+col notin xy_sum: dfs(col_list+[col],xy_diff+[cur_row-col],xy_sum+[cur_row+col]) ress = [] dfs([],[],[]) returnlen(ress)
classSolution(object): defspiralOrder(self, matrix): """ :type matrix: List[List[int]] :rtype: List[int] """ ifnot matrix: return [] R = len(matrix) C = len(matrix[0]) seen = [[False]*C for _ in matrix] dr = [0,1,0,-1] dc = [1,0,-1,0] r = c = di = 0 ans = [] for _ inrange(R*C): ans.append(matrix[r][c]) seen[r][c] = True next_r,next_c = r+dr[di],c+dc[di] if0<= next_r < R and0<= next_c < C andnot seen[next_r][next_c]: r = next_r c = next_c else: di = (di+1)%4 r = r + dr[di] c = c + dc[di] return ans
classSolution(object): defcanJump(self, nums): """ :type nums: List[int] :rtype: bool """ last = len(nums)-1 for i inrange(len(nums)-1,-1,-1): if i + nums[i] >= last: last = i return last == 0
classSolution(object): defrotate(self, matrix): """ :type matrix: List[List[int]] :rtype: None Do not return anything, modify matrix in-place instead. """ row = len(matrix) col = len(matrix[0]) for i inrange(row): for j inrange(i,col): matrix[i][j],matrix[j][i] = matrix[j][i],matrix[i][j] for i inrange(row): matrix[i].reverse()
classSolution(object): defmyPow(self, x, n): """ :type x: float :type n: int :rtype: float """ if n < 0: x = 1/x n = -n res = 1 while n: if n & 1: res *= x x *= x n >>= 1 return res
也可以用递归,递归的坏处在于可能发生递归调用栈溢出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution(object): defmyPow(self, x, n): """ :type x: float :type n: int :rtype: float """ if n == 0: return1 if n < 0: return self.myPow(1/x,-n) if n & 1: return x * self.myPow(x*x,n>>1) else: return self.myPow(x*x,n>>1)