1. 买卖股票的最佳时机(Easy)
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
如果你最多只允许完成一笔交易(即买入和卖出一支股票),设计一个算法来计算你所能获取的最大利润。
注意你不能在买入股票前卖出股票。
示例 1:
1 | 输入: [7,1,5,3,6,4] |
示例 2:
1 | 输入: [7,6,4,3,1] |
解答:
思路:很简单的动态规划题目。
遍历数组找到当前最低价格,用当天价格减去最低价格获得最大利润
1 | class Solution(object): |
2. 买卖股票的最佳时机2(Easy)
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
1 | 输入: [7,1,5,3,6,4] |
示例 2:
1 | 输入: [1,2,3,4,5] |
示例 3:
1 | 输入: [7,6,4,3,1] |
解答:
思路:也是动态规划,只不过是多了几次交易。
- 考虑买股票的策略:设今天价格p1,明天价格p2,若p1 < p2则今天买入明天卖出,赚取p2 - p1;
- 若遇到连续上涨的交易日,第一天买最后一天卖收益最大,等价于每天买卖(因为没有交易手续费);
- 遇到价格下降的交易日,不买卖,因此永远不会亏钱。
- 赚到了所有交易日的钱,所有亏钱的交易日都未交易,理所当然会利益最大化。\
1 | class Solution(object): |
3. 买卖股票的最佳时机3(Hard)
给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。
注意: 你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
1 | 输入: [3,3,5,0,0,3,1,4] |
示例 2:
1 | 输入: [1,2,3,4,5] |
示例 3:
1 | 输入: [7,6,4,3,1] |
解答:
思路:依旧是动态规划
动态规划
dp[k][i]到第i天经过k次交易得到最大的利润.
动态方程: dp[k][i] = max(dp[k][i-1], dp[k-1][j-1] + prices[i] - prices[j]) 0 <=j <= i
1 | class Solution(object): |
4. 二叉树中最大路径和(Hard)
给定一个非空二叉树,返回其最大路径和。
本题中,路径被定义为一条从树中任意节点出发,达到任意节点的序列。该路径至少包含一个节点,且不一定经过根节点。
示例 1:
1 | 输入: [1,2,3] |
示例 2:
1 | 输入: [-10,9,20,null,null,15,7] |
解答:
思路:
根据题意,最大路径和可能出现在:
- 左子树中
- 右子树中
- 包含根节点与左右子树
我们的思路是递归从bottom向topreturn的过程中,记录左子树和右子树中路径更大的那个,并向父节点提供当前节点和子树组成的最大值。
递归设计:
返回值:
1
(root.val) + max(left, right)
即此节点与左右子树最大值之和,较差的解直接被舍弃,不会再被用到。
- 需要注意的是,若计算结果
tmp <= 0,意味着对根节点有负贡献,不会在任何情况选这条路(父节点中止),因此返回0。
- 需要注意的是,若计算结果
递归终止条件:越过叶子节点,返回
0;记录最大值:当前节点
最大值 = root.val + left + right。
最终返回所有路径中的全局最大值即可。
1 | # Definition for a binary tree node. |
5. 验证回文串(Easy)
给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。
说明:本题中,我们将空字符串定义为有效的回文串。
示例 1:
1 | 输入: "A man, a plan, a canal: Panama" |
示例 2:
1 | 输入: "race a car" |
解答:
思路:回文串问题,双指针法
1 | class Solution(object): |
6. 单词接龙2(Hard)
给定两个单词(beginWord 和 endWord)和一个字典 wordList,找出所有从 beginWord 到 endWord 的最短转换序列。转换需遵循如下规则:
- 每次转换只能改变一个字母。
- 转换过程中的中间单词必须是字典中的单词。
说明:
- 如果不存在这样的转换序列,返回一个空列表。
- 所有单词具有相同的长度。
- 所有单词只由小写字母组成。
- 字典中不存在重复的单词。
- 你可以假设 beginWord 和 endWord 是非空的,且二者不相同。
示例 1:
1 | 输入: |
示例 2:
1 | 输入: |
解答:
思路:DFS + BFS
用BFS求从beginWord 到endWord最短距离,经过哪些单词, 用字典记录离beginWord的距离;
用DFS求从beginWord 到endWord有哪些路径.
1 | class Solution(object): |
当然,这道题一看,标准的回溯法,基本的BFS,典型的level order traverse
有两个坑:
- 不要判断字典里的某两个word是否只相差一个字母,而是要判断某个word的邻居(和他只相差一个字母的所有word)是否在字典里,这样的改进会使这一步的复杂度下降很多,否则超时妥妥
- 每一轮访问过的word一定要从字典中删除掉,否则一定会超时
最后见到end word就收
完成
拿题目的例子来看:
1 | hit |
routine 字典,然后再根据这个来寻找路径
‘cog’: [‘log’, ‘dog’]这里的意思就是说在走到‘cog’之前尝试过了‘log’和‘dog’```,即previous tried node
而生成字典的过程就是BFS的,此处保证寻找的路径就是最短的。
1 | class Solution(object): |
7. 单词接龙(Medium)
给定两个单词(beginWord 和 endWord)和一个字典,找到从 beginWord到 endWord 的最短转换序列的长度。转换需遵循如下规则:
- 每次转换只能改变一个字母。
- 转换过程中的中间单词必须是字典中的单词。
说明:
- 如果不存在这样的转换序列,返回 0。
- 所有单词具有相同的长度。
- 所有单词只由小写字母组成。
- 字典中不存在重复的单词。
- 你可以假设 beginWord 和 endWord 是非空的,且二者不相同。
示例 1:
1 | 输入: |
示例 2:
1 | 输入: |
解答:
思路:
类似于层次遍历,画成树结构就很好看了,求树的深度。
1 | class Solution(object): |
8. 最长连续序列(Hard)
给定一个未排序的整数数组,找出最长连续序列的长度。
要求算法的时间复杂度为 *O(n)*。
示例:
1 | 输入: [100, 4, 200, 1, 3, 2] |
解答:
思路:
这道题思路很巧妙,判断每个数后续是否在数组中
1 | class Solution(object): |
9. 求根到叶子结点数字之和(Medium)
给定一个二叉树,它的每个结点都存放一个 0-9 的数字,每条从根到叶子节点的路径都代表一个数字。
例如,从根到叶子节点路径 1->2->3 代表数字 123。
计算从根到叶子节点生成的所有数字之和。
说明: 叶子节点是指没有子节点的节点。
示例 1:
1 | 输入: [1,2,3] |
示例 2:
1 | 输入: [4,9,0,5,1] |
解答:
思路:DFS遍历
1 | # Definition for a binary tree node. |
10. 被围绕的区域(Medium)
给定一个二维的矩阵,包含 'X' 和 'O'(字母 O)。
找到所有被 'X' 围绕的区域,并将这些区域里所有的 'O' 用 'X' 填充。
示例:
1 | X X X X |
运行你的函数后,矩阵变为:
1 | X X X X |
解释:
被围绕的区间不会存在于边界上,换句话说,任何边界上的 'O' 都不会被填充为 'X'。 任何不在边界上,或不与边界上的 'O' 相连的 'O' 最终都会被填充为 'X'。如果两个元素在水平或垂直方向相邻,则称它们是“相连”的。
解答:
思路:
反向找答案,先把非围绕区域的”O”找出来,然后把这些区域标记,最后将剩余的”O”换成X,标记区域换回去,表示为”O”
1 | class Solution(object): |
11. 分割回文串(Medium)
给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串。
返回 s 所有可能的分割方案。
示例:
1 | 输入: "aab" |
解答:
思路:
很标准的回溯法,针对可能的每一个分割点,如果前面是回文,则递归判断后面。
1 | class Solution(object): |
12. 分割回文串2(Hard)
给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串。
返回符合要求的最少分割次数。
示例:
1 | 输入: "aab" |
解答:
思路:
如果还是用上一题的思路,结果超时。
1 | class Solution(object): |
所以,使用动态规划。
很容易理解。
如果s[j:i]是回文,那么cut[i] =min(cut[i],cut[j-1]+1)
怎么判断回文,用DP数组。
1 | class Solution(object): |
13. 克隆图(Medium)
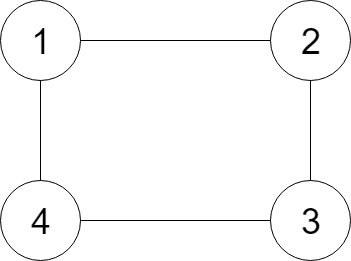
给定无向连通图中一个节点的引用,返回该图的深拷贝(克隆)。图中的每个节点都包含它的值 val(Int) 和其邻居的列表(list[Node])。
示例:
1 | 输入: |
提示:
- 节点数介于 1 到 100 之间。
- 无向图是一个简单图,这意味着图中没有重复的边,也没有自环。
- 由于图是无向的,如果节点 p 是节点 q 的邻居,那么节点 q 也必须是节点 p 的邻居。
- 必须将给定节点的拷贝作为对克隆图的引用返回。
解答:
思路::典型的DFS或者BFS
DFS方法
1 | """ |
BFS方法
1 | """ |
14. 加油站(Medium)
在一条环路上有 N 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1。
说明:
- 如果题目有解,该答案即为唯一答案。
- 输入数组均为非空数组,且长度相同。
- 输入数组中的元素均为非负数。
示例 1:
1 | 输入: |
示例 2:
1 | 输入: |
解答:
思路:贪心算法
每一次到达一个加油站,更新total和cur,如果cur<0,说明到达不了下一站,以下一站为起点重新开始。
贪心在于以下一点为起始。
从上一次重置的加油站到当前加油站的任意一个加油站出发,到达当前加油站之前, cur 也一定会比 0 小
1 | class Solution(object): |
15. 分发糖果(Hard)
老师想给孩子们分发糖果,有 N 个孩子站成了一条直线,老师会根据每个孩子的表现,预先给他们评分。
你需要按照以下要求,帮助老师给这些孩子分发糖果:
- 每个孩子至少分配到 1 个糖果。
- 相邻的孩子中,评分高的孩子必须获得更多的糖果。
那么这样下来,老师至少需要准备多少颗糖果呢?
示例 1:
1 | 输入: [1,0,2] |
示例 2:
1 | 输入: [1,2,2] |
解答:
思路:
- 首先我们从左往右边看,如果当前child的rating比它左边child的rating大,那么当前child分的candy肯定要比它左边多1
- 然后从右往左边看,如果当前child的rating比它右边child的rating大,那么当前child分的candy肯定要比它右边多1
1 | class Solution(object): |
还有一种空间复杂度更低的做法
就是寻找连续下降的长度,然后加上连续下降长度所需的糖果数,同时更新之前的糖果值
最终的是下面的pre和des
以及怎么计算res
1 | class Solution(object): |
16. 只出现一次的数字(Medium)
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
说明:
你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
示例 1:
1 | 输入: [2,2,1] |
示例 2:
1 | 输入: [4,1,2,1,2] |
解答:
思路:
就很简单,用异或,剑指offer原题
1 | class Solution(object): |
17. 只出现一次的数字2(Medium)
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现了三次。找出那个只出现了一次的元素。
说明:
你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
示例 1:
1 | 输入: [2,2,3,2] |
示例 2:
1 | 输入: [0,1,0,1,0,1,99] |
解答:
思路:
首先我们会定义两个变量ones和twos,当遍历nums的时候,对于重复元素x,第一次碰到x的时候,我们会将x赋给ones,第二次碰到后再赋给twos,第三次碰到就全部消除。赋值和消除的动作可以通过xor很简单的实现。所以我们就可以写出这样的代码
1 | ones = (ones^num) |
但是上面写法忽略了,只有当ones是x的时候,我们会将0赋给twos,那要怎么做呢?我们知道如果b=0,那么b^num就变成了x,而x&~x就完成了消除操作.所以代码应该写成:
1 | ones = (ones^num)&~(twos) |
第一次出现x记录在ones中,并且此时twos应为0;第二次出现x记录在twos中,同时ones置为0,;第三次出现x,则ones,twos均重置为0
例如:第一个数:10,则ones = 10,twos = 0,第二个数10,则ones = 0, twos = 10, 第三个数10, 则ones= 0,twos=0
1 | class Solution(object): |
若题目改成找只出现两次的数,则return twos
思路二:按位求和
长度为32的数组,将每个数按照二进制位1或者0求和,最后与1异或还原
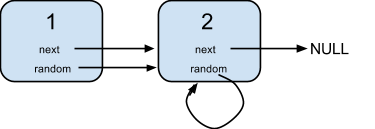
18. 复制带随机指针的链表(Hard)
给定一个链表,每个节点包含一个额外增加的随机指针,该指针可以指向链表中的任何节点或空节点。
要求返回这个链表的深拷贝。
示例:
1 | 输入: |
提示:
- 你必须返回给定头的拷贝作为对克隆列表的引用。
解答:
思路:
这个题是剑指offer原题,有好几种做法
一种是先复制,再拆分,在拼接的过程
一种是用哈希表映射原节点和新节点。
1 | """ |
19. 单词拆分(Medium)
给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。
说明:
- 拆分时可以重复使用字典中的单词。
- 你可以假设字典中没有重复的单词。
示例 1:
1 | 输入: s = "leetcode", wordDict = ["leet", "code"] |
示例 2:
1 | 输入: s = "applepenapple", wordDict = ["apple", "pen"] |
示例 3:
1 | 输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"] |
思路:
比较愚蠢的动态规划思想,当然回溯法肯定会超时
1 | class Solution(object): |
还有另一种更加高效的回溯算法,在wordDict最长长度内寻找
1 | class Solution(object): |
20. 单词拆分2(Hard)
给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,在字符串中增加空格来构建一个句子,使得句子中所有的单词都在词典中。返回所有这些可能的句子。
说明:
- 分隔时可以重复使用字典中的单词。
- 你可以假设字典中没有重复的单词。
示例 1:
1 | 输入: |
示例 2:
1 | 输入: |
示例 3:
1 | 输入: |
解答:
思路:
这道题就是一个很简单的DFS,也就是深度回溯算法
但是很可惜,超时。
1 | class Solution(object): |
另一种思路是,用cache加速后的回溯算法,不会超时。
1 | class Solution(object): |