classSolution(object): deffirstMissingPositive(self, nums): """ :type nums: List[int] :rtype: int """ if1notin nums: return1 iflen(nums) == 1: return2 for i inrange(len(nums)): if nums[i]<= 0or nums[i] > len(nums): nums[i] = 1 for i inrange(len(nums)): a = abs(nums[i]) if a == len(nums): nums[0] = -abs(nums[0]) else: nums[a] = -abs(nums[a]) for i inrange(1,len(nums)): if nums[i]>0: return i if nums[0] > 0: returnlen(nums) returnlen(nums)+1
classSolution(object): deftrap(self, height): """ :type height: List[int] :rtype: int """ l,r = 0,len(height)-1 water = 0 min_height = 0 while l < r: min_height = min(height[l],height[r]) while l < r and height[l] <= min_height: water += min_height - height[l] l += 1 while l < r and height[r] <= min_height: water += min_height - height[r] r -= 1 return water
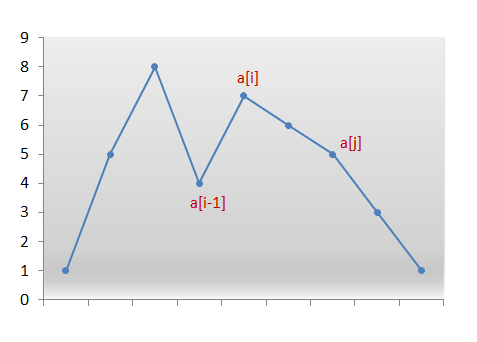
classSolution(object): defjump(self, nums): """ :type nums: List[int] :rtype: int """ iflen(nums)<2: return0 cur = nums[0] pre = nums[0] res = 1 for i inrange(len(nums)): if cur < i: cur = pre res += 1 pre = max(pre,i + nums[i]) return res
另一份AC代码可能更好理解:
cur_far表示当前下一步可跳最远距离
cur_end表示上一跳所跳的位置
i表示当前所在的位置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution: defjump(self, nums): """ :type nums: List[int] :rtype: int """ cur_end, cur_farthest, step = 0, 0, 0 for i inrange(len(nums)-1): cur_farthest = max(cur_farthest, i+nums[i]) if cur_farthest >= len(nums) - 1: step += 1 return step if i == cur_end: cur_end = cur_farthest step += 1 return step
Very elegant method, but it took me a long time to understand. Some comment for the above:
e: longest distance in current minimum step
sc: minimum steps for reaching e
From i to e, even max is changed in a loop, it is reachable in one step.
思路三:动态规划
超级容易理解。 dp[i]代表的是到达index为i的位置的最少步数, 依然超时。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
classSolution: defjump(self, nums): """ :type nums: List[int] :rtype: int """ ifnot nums orlen(nums) == 0: return0 dp = [sys.maxsize] * len(nums) dp[0] = 0 for i inrange(1, len(nums)): for j inrange(i): if j + nums[j] >= i: dp[i] = min(dp[i], dp[j]+1) return dp[-1]
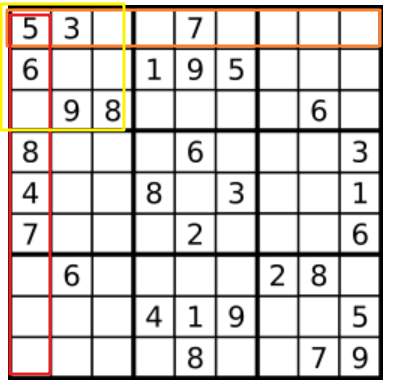
def isValidSudoku(self, board):
"""
:type board: List[List[str]]
:rtype: bool
"""
row = [{} for i in range(len(board))]
col = [{} for j in range(len(board[0]))]
box = [{} for i in range(len(board))]
for i in range(9):
for j in range(9):
num = board[i][j]
if num != '.':
num = int(num)
box_index = (i//3)*3+j//3
row[i][num] = row[i].get(num,0)+1
col[j][num] = col[j].get(num,0)+1
box[box_index][num] = box[box_index].get(num,0)+1
if row[i][num]>1 or col[j][num]>1 or box[box_index][num]>1:
return False
return True
```python class Solution(object): def solveSudoku(self, board): """ :type board: List[List[str]] :rtype: None Do not return anything, modify board in-place instead. """ self.backtrack(board) def backtrack(self,board): for i in range(9): for j in range(9): if board[i][j] == '.': for c in '123456789': if self.isPointValid(board,i,j,c): board[i][j] = c if self.backtrack(board): return True else: board[i][j] = '.' return False return True def isPointValid(self,board,x,y,c): for i in range(9): if board[i][y] == c: return False if board[x][i] == c: return False if board[(x//3)*3+i//3][(y//3)*3+i%3] == c: return False return True
classSolution(object): defcountAndSay(self, n): """ :type n: int :rtype: str """ if n == 1: return'1' s = self.countAndSay(n-1) + '*' res,count = '',1 for i inrange(len(s)-1): if s[i]==s[i+1]: count += 1 else: res += str(count) + str(s[i]) count = 1 return res
classSolution(object): defcountAndSay(self, n): """ :type n: int :rtype: str """ defnext_num(tmp): n = len(tmp) res = '' i = 0 while i < n: count = 1 while i < n-1and tmp[i] == tmp[i+1]: count += 1 i += 1 res += str(count)+str(tmp[i]) i += 1 return res res = '1' for i inrange(1,n): res = next_num(res) return res
classSolution(object): defcombinationSum(self, candidates, target): """ :type candidates: List[int] :type target: int :rtype: List[List[int]] """ candidates.sort() n = len(candidates) res = [] defbacktrack(i,tmp_sum,tmp): if tmp_sum > target or i == n: return if tmp_sum == target: res.append(tmp) return for j inrange(i,n): if tmp_sum + candidates[j]>target: break backtrack(j,tmp_sum+candidates[j],tmp+[candidates[j]]) backtrack(0,0,[]) return res
classSolution(object): deflongestValidParentheses(self, s): """ :type s: str :rtype: int """ iflen(s) == 0: return0 dp = [0for i inrange(len(s))] for i inrange(1,len(s)): if s[i] == ')': left = i-1-dp[i-1] if left >= 0and s[left] == '(': dp[i] = dp[i-1]+2 if left > 0: dp[i] += dp[left-1] returnmax(dp)
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝 int len = removeDuplicates(nums);
// 在函数里修改输入数组对于调用者是可见的。 // 根据你的函数返回的长度, 它会打印出数组中该长度范围内的所有元素。 for (int i = 0; i < len; i++) { print(nums[i]); }
解答:
思路一:双指针法
快指针遍历旧数组,满指针指向新数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution(object): defremoveDuplicates(self, nums): """ :type nums: List[int] :rtype: int """ iflen(nums) == 0: return0 slow = 0 for fast inrange(len(nums)): if nums[slow] != nums[fast]: slow += 1 nums[slow] = nums[fast] return slow+1
思路二:
很简单,一看就明白
1 2 3 4 5 6 7 8 9 10 11 12
classSolution(object): defremoveDuplicates(self, nums): """ :type nums: List[int] :rtype: int """ idx = 0 for num in nums: if idx < 1or num != nums[idx-1]: nums[idx] = num idx += 1 return idx
2. 移除元素(Easy)
给定一个数组 nums 和一个值 val,你需要原地移除所有数值等于 val 的元素,返回移除后数组的新长度。
不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件下完成。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
示例 1:
1 2 3 4 5
给定 nums = [3,2,2,3], val = 3,
函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。
你不需要考虑数组中超出新长度后面的元素。
示例 2:
1 2 3 4 5 6 7
给定 nums = [0,1,2,2,3,0,4,2], val = 2,
函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。
注意这五个元素可为任意顺序。
你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以“引用”方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
1 2 3 4 5 6 7 8
// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝 int len = removeElement(nums, val);
// 在函数里修改输入数组对于调用者是可见的。 // 根据你的函数返回的长度, 它会打印出数组中该长度范围内的所有元素。 for (int i = 0; i < len; i++) { print(nums[i]); }
classSolution(object): deffindSubstring(self, s, words): """ :type s: str :type words: List[str] :rtype: List[int] """ from collections import Counter ifnot s ornot words: return [] one_word = len(words[0]) word_num = len(words) n = len(s) if n < one_word: return [] words = Counter(words) res = [] for i inrange(0,one_word): cur_cnt = 0 left = i right = i cur_Counter = Counter() while right+one_word<=n: w = s[right:right+one_word] right += one_word if w notin words: left = right cur_Counter.clear() cur_cnt = 0 else: cur_Counter[w] += 1 cur_cnt += 1 while cur_Counter[w] > words[w]: left_w = s[left:left+one_word] left += one_word cur_Counter[left_w] -= 1 cur_cnt -= 1 if cur_cnt == word_num: res.append(left) return res
classSolution(object): defmergeKLists(self, lists): """ :type lists: List[ListNode] :rtype: ListNode """ self.nodes = [] head = point = ListNode(0) for l in lists: while l: self.nodes.append(l.val) l = l.next for x insorted(self.nodes): point.next = ListNode(x) point = point.next return head.next
# Definition for singly-linked list. # class ListNode(object): # def __init__(self, x): # self.val = x # self.next = None classSolution(object): defswapPairs(self, head): """ :type head: ListNode :rtype: ListNode """ ifnot head ornot head.next: return head cur = dummy = ListNode(-1) dummy.next = head while cur.nextand cur.next.next: one,two,three = cur.next,cur.next.next,cur.next.next.next cur.next = two two.next = one one.next = three cur = one return dummy.next
# Definition for singly-linked list. # class ListNode(object): # def __init__(self, x): # self.val = x # self.next = None classSolution(object): defreverseKGroup(self, head, k): """ :type head: ListNode :type k: int :rtype: ListNode """ cur = head cnt = 0 while cur and cnt != k: cur = cur.next cnt += 1 if cnt == k: cur = self.reverseKGroup(cur,k) while cnt: tmp = head.next head.next = cur cur = head head = tmp cnt -= 1 head = cur return head
classSolution(object): defthreeSumClosest(self, nums, target): """ :type nums: List[int] :type target: int :rtype: int """ nums.sort() n = len(nums) res = float('inf') for i inrange(n): if i > 0and nums[i] == nums[i-1]: continue l = i+1 r = n-1 while l < r: cur = nums[i] + nums[l] + nums[r] if cur == target: return target ifabs(res - target) > abs(cur - target): res = cur if cur > target: r -= 1 if cur < target: l += 1 return res
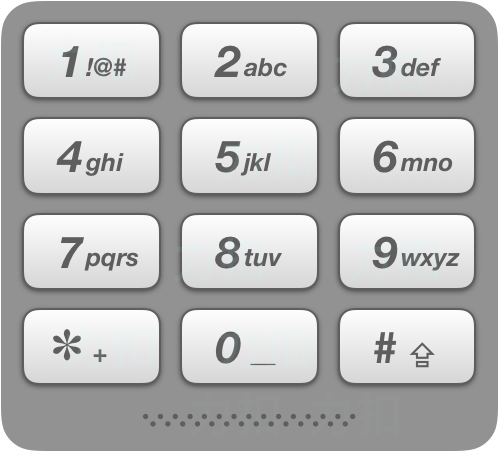
classSolution(object): defletterCombinations(self, digits): """ :type digits: str :rtype: List[str] """ num2char = {'2':['a','b','c'], '3':['d','e','f'], '4':['g','h','i'], '5':['j','k','l'], '6':['m','n','o'], '7':['p','q','r','s'], '8':['t','u','v'], '9':['w','x','y','z']} ifnot digits: return [] res = [""] for num in digits: next_res = [] for alp in num2char[num]: for tmp in res: next_res.append(tmp + alp) res = next_res return res
执行用时 :16 ms, 在所有 Python 提交中击败了99.12%的用户
3. 四数之和(Medium)
给定一个包含 n 个整数的数组 nums 和一个目标值 target,判断 nums 中是否存在四个元素 a,b,c 和 d ,使得 a + b + c + d 的值与 target 相等?找出所有满足条件且不重复的四元组。
classSolution(object): deffourSum(self, nums, target): """ :type nums: List[int] :type target: int :rtype: List[List[int]] """ n = len(nums) if n < 4: return [] nums.sort() res = [] for i inrange(n-3): if i > 0and nums[i] == nums[i-1]: continue if nums[i] + nums[i+1] + nums[i+2] + nums[i+3] > target: break if nums[i] + nums[n-1] + nums[n-2] + nums[n-2] < target: continue for j inrange(i+1,n-2): if j - i > 1and nums[j] == nums[j-1]: continue if nums[i] + nums[j] + nums[j+1] + nums[j+2] > target: break if nums[i] + nums[j] + nums[n-1] + nums[n-2] < target: continue l = j+1 r = n-1 while l < r: tmp = nums[i] + nums[j] + nums[l] + nums[r] if tmp == target: res.append([nums[i],nums[j],nums[l],nums[r]]) while l < r and nums[l] == nums[l+1]: l += 1 while l < r and nums[r] == nums[r-1]: r -= 1 if tmp > target: r -= 1 else: l += 1 return res
classSolution(object): defisMatch(self, s, p): """ :type s: str :type p: str :rtype: bool """ dp = [[False] * (len(p)+1) for _ inrange(len(s)+1)] dp[-1][-1] = True for i inrange(len(s),-1,-1): for j inrange(len(p)-1,-1,-1): first = i<len(s) and p[j] in {s[i],'.'} if j+1 < len(p) and p[j+1] == '*': dp[i][j] = dp[i][j+2] or first and dp[i+1][j] else: dp[i][j] = first and dp[i+1][j+1] return dp[0][0]
我们设置两个指针 left 和 right,分别指向数组的最左端和最右端。此时,两条垂直线的距离是最远的,若要下一个矩阵面积比当前面积来得大,必须要把 height[left] 和 height[right] 中较短的垂直线往中间移动,看看是否可以找到更长的垂直线。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classSolution(object): defmaxArea(self, height): """ :type height: List[int] :rtype: int """ left = 0 right = len(height) - 1 area = 0 while left < right: area = max(area,min(height[left], height[right]) * (right - left)) if height[left] < height[right]: left += 1 else: right -= 1 return area
3. 整数转罗马数字(Medium)
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
1 2 3 4 5 6 7 8
字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000
例如,罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
classSolution(object): defintToRoman(self, num): """ :type num: int :rtype: str """ lookup = { 1:'I', 4:'IV', 5:'V', 9:'IX', 10:'X', 40:'XL', 50:'L', 90:'XC', 100:'C', 400:'CD', 500:'D', 900:'CM', 1000:'M' } res = '' for key insorted(lookup.keys())[::-1]: a = num // key if a == 0: continue res += (lookup[key] * a) num -= a * key if num == 0: break return res
4. 罗马数字转整数(Easy)
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
1 2 3 4 5 6 7 8
字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
```python class Solution(object): def romanToInt(self, s): """ :type s: str :rtype: int """ lookup = { 'I': 1, 'V': 5, 'X': 10, 'L': 50, 'C': 100, 'D': 500, 'M': 1000 } res = 0 for i in range(len(s)): if i > 0 and lookup[s[i]] > lookup[s[i-1]]: res += lookup[s[i]] - 2 * lookup[s[i-1]] else: res += lookup[s[i]] return res
classSolution(object): defthreeSum(self, nums): """ :type nums: List[int] :rtype: List[List[int]] """ n = len(nums) res = [] nums.sort() for i inrange(n): for j inrange(i,n): for k inrange(j,n): if nums[i] + nums[j] + nums[k] == 0and j != i and k != j and k != i: curRes = [nums[i],nums[j],nums[k]] if curRes notin res: res.append(curRes)
classSolution: defthreeSum(self, nums: List[int]) -> List[List[int]]: nums.sort() n = len(nums) res = [] for i inrange(n): if i > 0and nums[i] == nums[i-1]: continue left = i + 1 right = n - 1 while left < right: cur_sum = nums[i] + nums[left] + nums[right] if cur_sum == 0: tmp = [nums[i],nums[left],nums[right]] res.append(tmp) while left < right and nums[left] == nums[left+1]: left += 1 while left < right and nums[right] == nums[right-1]: right -= 1 left += 1 right -= 1 elif cur_sum > 0: right -= 1 else: left += 1 return res
classSolution(object): defthreeSum(self, nums): """ :type nums: List[int] :rtype: List[List[int]] """ dic = {} res = [] for i in nums: if i in dic: dic[i] += 1 else: dic[i] = 1 pos =[i for i in dic if i > 0] neg =[i for i in dic if i < 0] neg.sort() if0in dic and dic[0] >= 3: res.append([0,0,0]) for i in pos: for j in neg: k = -i-j if k in dic: if (k==i or k==j) and dic[k] >= 2: res.append([i,k,j]) elif i>k>j: res.append([i,k,j]) if k < j: break return res
classSolution(object): defreverse(self, x): """ :type x: int :rtype: int """ if x < 0: return -self.reverse(-x) res = 0 while x: res = res * 10 + x%10 x //= 10 return res if res <= 0x7fffffffelse0
classSolution(object): defisPalindrome(self, x): """ :type x: int :rtype: bool """ if x < 0or (x%10 == 0and x != 0): returnFalse res = 0 while x > res: res = res * 10 + x%10 x //= 10 return x == res or x == res/10
思路二:时间复杂度$O(1)$,空间复杂度$O(1)$
排除负数
通过字符串进行反转,对比数字是否相等就行
class Solution:
def isPalindrome(self, x):
"""
:type x: int
:rtype: bool
"""
if x < 0:
return False
elif x != int(str(x)[::-1]):
return False
else:
return True
classSolution(object): deffindMedianSortedArrays(self, nums1, nums2): """ :type nums1: List[int] :type nums2: List[int] :rtype: float """ deffindKth(A,B,k): iflen(A) == 0: return B[k-1] iflen(B) == 0: return A[k-1] if k == 1: returnmin(A[0],B[0]) a = A[k//2-1] iflen(A) >= k // 2elseNone b = B[k//2-1] iflen(B) >= k // 2elseNone # if a is None: # return findKth(A, B[k // 2:], k - k // 2) # 这里要注意:因为 k//2 不一定等于 (k - k//2) # if b is None: # return findKth(A[k // 2:], B, k - k // 2) # if a < b: # return findKth(A[k // 2:], B, k - k // 2) # else: # return findKth(A, B[k // 2:], k - k // 2)
if b isNoneor (a isnotNoneand a < b): return findKth(A[k // 2:], B, k - k // 2) return findKth(A, B[k // 2:], k - k // 2) n = len(nums1) + len(nums2) if n % 2 == 1: return findKth(nums1,nums2,n//2+1) else: small = findKth(nums1,nums2,n//2) large = findKth(nums1,nums2,n//2+1) return (small + large) / 2.0
classSolution(object): deffindMedianSortedArrays(self, nums1, nums2): """ :type nums1: List[int] :type nums2: List[int] :rtype: float """ deffindKth(A, pa, B, pb, k): res = 0 m = 0 while pa < len(A) and pb < len(B) and m < k: if A[pa] < B[pb]: res = A[pa] pa += 1 else: res = B[pb] pb += 1 m += 1 while pa < len(A) and m < k: res = A[pa] pa += 1 m += 1 while pb < len(B) and m < k: res = B[pb] pb += 1 m += 1 return res n = len(nums1) + len(nums2) if n % 2 == 1: return findKth(nums1, 0, nums2, 0, n // 2 + 1) else: smaller = findKth(nums1, 0, nums2, 0, n // 2) bigger = findKth(nums1, 0, nums2, 0, n // 2 + 1) return (smaller + bigger) / 2.0
2. 最长回文字串(Medium)
给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
示例 1:
1 2 3
输入: "babad" 输出: "bab" 注意: "aba" 也是一个有效答案。
示例 2:
1 2
输入: "cbbd" 输出: "bb"
解答:
思路一:时间复杂度$O(n^2)$,空间复杂度$O(n^2)$
动态规划思想:dp[i][j]表示s[i:j+1]是否是palindrome
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classSolution(object): deflongestPalindrome(self, s): """ :type s: str :rtype: str """ res = '' dp = [[False] * len(s) for i inrange(len(s))] for i inrange(len(s),-1,-1): for j inrange(i,len(s)): dp[i][j] = (s[i] == s[j]) and (j-i<3or dp[i+1][j-1]) if dp[i][j] and j-i+1>len(res): res = s[i:j+1] return res
思路二:时间复杂度$O(n^2)$,空间复杂度$O(1)$
回文字符串长度为奇数和偶数是不一样的:
奇数:'xxx s[i] xxx', 比如 'abcdcba'
偶数:'xxx s[i] s[i+1] xxx', 比如 'abcddcba'
我们区分回文字符串长度为奇数和偶数的情况,然后依次把每一个字符当做回文字符串的中间字符,向左右扩展到满足回文的最大长度,不停更新满足回文条件的最长子串的左右index: l 和r,最后返回s[l:r+1]即为结果。
classSolution(object): deflongestPalindrome(self, s): """ :type s: str :rtype: str """ l = 0# left index of the current substring r = 0# right index of the current substring max_len = 0# length of the longest palindromic substring for now n = len(s) for i inrange(n): # odd case: 'xxx s[i] xxx', such as 'abcdcba' for j inrange(min(i+1, n-i)): # 向左最多移动 i 位,向右最多移动 (n-1-i) 位 if s[i-j] != s[i+j]: # 不对称了就不用继续往下判断了 break if2 * j + 1 > max_len: # 如果当前子串长度大于目前最长长度 max_len = 2 * j + 1 l = i - j r = i + j
# even case: 'xxx s[i] s[i+1] xxx', such as 'abcddcba' if i+1 < n and s[i] == s[i+1]: for j inrange(min(i+1, n-i-1)): # s[i]向左最多移动 i 位,s[i+1]向右最多移动 [n-1-(i+1)] 位 if s[i-j] != s[i+1+j]: # 不对称了就不用继续往下判断了 break if2 * j + 2 > max_len: max_len = 2 * j + 2 l = i - j r = i + 1 + j return s[l:r+1]
classSolution(object): defconvert(self, s, numRows): """ :type s: str :type numRows: int :rtype: str """ if numRows == 1orlen(s) <= numRows: return s res = [''] * numRows idx,step = 0,1 for c in s: res[idx] += c if idx == 0: step = 1 elif idx == numRows - 1: step = -1 idx += step return''.join(res)
思路二:模拟过程
Z字形,就是两种状态,一种垂直向下,还有一种斜向上
控制好边界情况就可以了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: defconvert(self, s: str, numRows: int) -> str: ifnot s: return"" if numRows == 1:return s s_Rows = [""] * numRows i = 0 n = len(s) while i < n: for j inrange(numRows): if i < n: s_Rows[j] += s[i] i += 1 for j inrange(numRows-2,0,-1): if i < n: s_Rows[j] += s[i] i += 1 return"".join(s_Rows)
classSolution(object): deflengthOfLongestSubstring(self, s): """ :type s: str :rtype: int """ lookup = collections.defaultdict(int) l,r,counter,res = 0,0,0,0 while r < len(s): lookup[s[r]] += 1 if lookup[s[r]] == 1: counter += 1 r += 1 while l < r and counter < r - l: lookup[s[l]] -= 1 if lookup[s[l]] == 0: counter -= 1 l += 1 res = max(res,r - l) return res